
文 | 周鑫雨
編輯 | 鄧詠儀
脊髓栓系綜合徵(TCS),一種在新生兒中發病率約為0.005~0.025%的罕見病,近日被ChatGPT成功診斷——此前,不幸罹患TCS的Alex已經問診了17名醫生。
ChatGPT的成功,無疑讓AI大模型在醫療界擲出了不小的水花。
實際上,自2023年5月以來,國內外如谷歌、英偉達、亞馬遜、騰訊、京東等科技巨頭,都已經率先開始了醫療大模型的布局——據不完全統計,截至2023年8月,光國內就發布了40多個醫療相關的AI模型。各家模型落地的場景也大同小異,主要集中在智能問診、影像診斷、知識查詢。
2023年9月19日,百度交了一份醫療大模型的作業:「靈醫大模型」。
除了大模型技術的總體躍進,百度發布醫療大模型撞上了政策開閘的東風。國家藥監局器審中心針對新一代AI技術,接連發布了《深度學習輔助決策軟體審評要點》《人工智慧醫療器械註冊審查指導原則(徵求意見稿)》等文件,在構建監管機制的同時,也釋放出了加快AI輔助醫療落地的信號。
至於商業化的底氣,則在於百度前期的客戶合作案例。
比如在和人民衛生出版社的合作中,靈醫大模型補足了標籤搜索的短板,讓醫生和病患通過自然語言描述就能夠找到相應的知識;
再比如,北大口腔醫院信息中心副主任曹戰強提到,大模型除了在疾病診斷上展現出更強的能力,同時還能處理多維度、複雜的醫院管理數據,提高醫療工作的效率和安全。比如一個病區有50個病人,包括不同階段的高血壓和心臟病患者,大模型就能根據病人數量、疾病嚴重程度等靈活安排醫生提前介入和手術的時間。
百度想把技能點加滿,模型要會看病、分診管理、醫生培訓
上述的實戰經驗,一方面為靈醫大模型的誕生積攢了脫敏臨床數據。
據官方介紹,靈醫大模型的訓練數據總量達到了千億Token,主要涵蓋「醫-患-藥」場景。比如醫院方的數據包括脫敏的臨床數據、知識圖譜等,患者的數據則主要來源於百度搜索積累的健康問答數據。

靈醫大模型的訓練數據來源。圖源:百度
另一方面,合作案例也為靈醫大模型的商業化落地探索了更多的場景。
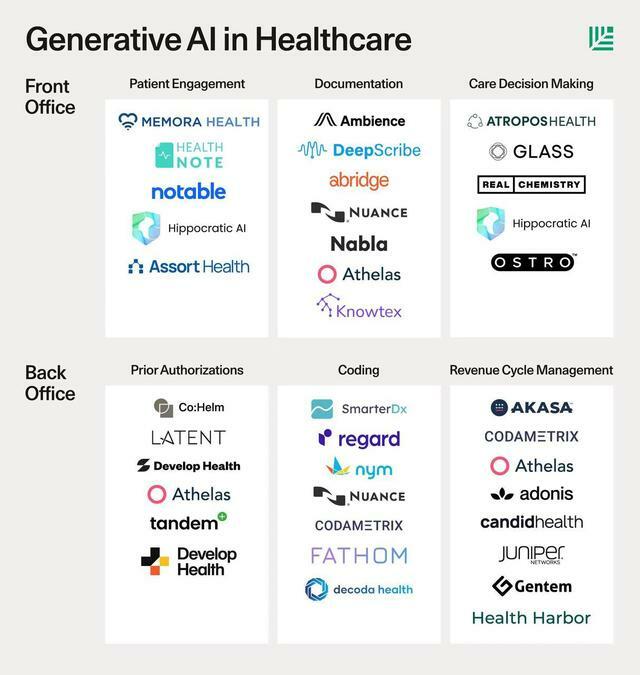
紅杉資本整理的醫療大模型的落地場景。圖源:紅杉資本
百度將靈醫大模型稱為國內「首個產業級」醫療大模型,原因在於靈醫一口吃下了目前大模型能落地的大部分醫療場景,包括文檔理解、病歷理解、醫療問答等。與此同時,百度的商業化野心不僅局限於醫院,還延伸至藥企、藥店、線上醫院等不同的醫療場景。

文檔理解
病歷理解:病歷生成、病歷問答

醫療問答:
具體到部署方式,由於各地醫療改革後,不少費用需要醫院科室承擔,成本昂貴的醫療大模型一開始就會「勸退」不少機構。
對此,百度採取的是因需制宜的策略,參數由大到小,推出了旗艦版(千億參數)、Lite版(十億、百億參數)、定製版(基於客戶數據定製)三種模型服務,可根據客戶對數據的敏感程度,採用私有部署或者公域部署的方式。

靈醫大模型的服務模式。圖源:作者拍攝
不過,將AI與事關生命健康的醫療結合,無異於刀尖起舞。
落地的阻力,首先在於監管政策的空白。此前,國家衛健委衛生發展研究中心副主任游茂在《第一財經》的採訪中就表示,AI醫療器械的專利數據,多集中在「機器學習」「醫學影像」領域,「自然與語言處理」「知識庫」等領域研究相對不足,「決策規則」領域研究幾乎空白。
更重要的問題是,目前醫療大模型的能力,是否足以與人類醫生媲美。
要想得知醫療AI的能力,「人機一致性測試」往往必不可少。所謂的人機一致性測試,指的是讓人和機器在同一場景下進行技能比拼。比如醫聯集團的MedGPT與三甲醫院醫生的診斷一致性達到96%;谷歌的Med-PaLM在醫學問答測試中,92.9%的答案與臨床醫生相當,92.9%的長篇答案符合科學共識。
即便在問診一致性上,部分醫療大模型已經達到一般醫生的水準,但落地到具體的診療場景仍然存在一定問題。比如MedGPT在問診過程中無法進行查體,以及無法給予患者更人性化的關懷。
靈醫大模型的能力,「接近三甲醫院的主治臨床醫生」
光從一場發布會,我們難以掂量靈醫大模型的真實斤兩。
「我也看了非常多的大模型的發布會,總體感覺大家都是在比參數、比性能、比排行榜。」百度集團資深副總裁、百度大健康事業群總裁何明科一開場,就直指國內大模型賽道「群模亂舞」。
那麼百度的靈醫大模型的性能能否在「群模」中脫穎而出?以及在落地過程中,醫療機構對AI大模型的接受度如何?
36氪同各家媒體,與百度大健康事業群AI產業部總經理劉軍偉、百度大健康事業群AI產業部研發負責人黃海峰等人展開了一場對話(內容略經編輯):
問:靈醫大模型在訓練數據這方面主要來源是哪些?在專業數據來源上相較於其他友商有哪些優勢?
黃海峰:首先大模型的數據其實是涵蓋了「醫-藥-患」三個方面,這也是百度做醫療大模型的優勢,能夠同時拿到醫院、線上患者、藥品的數據。百度有百度健康,有智慧醫療,還有醫療信息數據提供商GBI,在數據維度上更全。
在數據質量上,百度搜索每天有2億次健康的檢索,包括智慧醫療的產品,在項目落地中對數據的理解更全面,包括數據的治理和數據質控的技術,也能保障用於訓練的數據從質量上更好。
問:那麼醫療大模型最為核心的訓練數據是哪一部分?問診記錄、臨床數據這些不同種類的數據的重要性是否有區別?
黃海峰:首先哪部分更核心沒有標準答案,面向不同的場景有不同的核心數據。比如要做病歷生成,對這個任務最有用的是真實的病歷數據,如果是一些科普問答類,最有用的可能是醫典的數據、醫患對話和真正的在線問診數據。
問:國內比較稀缺的訓練數據是什麼?百度獲取這些數據的渠道是什麼?
黃海峰:這些類型的數據我們基本上都有,在類型上是比較全的。從獲取的渠道上來講,公開和私有化都有。公開的是網際網路的數據,我們會做嚴格的質量篩選,因為質量參差不齊。我們也會經過多種的策略,通過一些小模型,首先對數據做一些預處理、清洗以及篩選的工作。
一些高質量的數據,像電子病歷的數據,一方面需要做嚴格的脫敏,甚至在醫院的環境下做小模型的訓練,讓這個模型能夠學到知識,然後做到數據不出院、模型出院。
在獲取數據上,最難的就是醫院的病歷數據。其他一些知識類的數據,像人衛出版社權威的知識數據,其實對於整個大模型來講是比較關鍵的。同時藥品相關的數據也很重要,我們今年收購了GBI,覆蓋了全球95%的跨國藥企,這麼多年積累的數據對模型有很大的幫助。
問:發布會沒有特別提到關於靈醫大模型性能方面的一些數據。此前百度有沒有做過類似人機一致性的評比?比如把醫生和大模型放在同樣一個場景下進行一些比較。
朱東緯(百度大健康事業群AI產業部產品負責人):分兩層,文心大模型的底座肯定會做通識性的測評,醫療大模型就跟人去比,評測集有兩個層級,第一個是百度內部的醫生團隊,第二個會找外部的三甲醫院醫生。
問:效果如何?
朱東緯:我們測試的結果是接近三甲醫院的主治臨床醫生。
問:醫療的嚴肅性可能決定它對差錯容忍度更低,相較於大模型在其他領域的應用,醫療場景的商業化會更困難一點嗎?
劉軍偉:首先做醫療有一個基本的理解:醫療本身是一個民生工程,它既有商業屬性,還有社會價值。
現在很多客戶會主動找我們來合作,之前我們都是做好服務、做好產品,自己主動找各種合作夥伴,今天我們發現有很多人,比如說剛才提到的不管是藥店甚至門診,都願意主動跟百度合作。同時我們的產品線是可以開放測試的,通過這些測試也發現確實有價值,因此商業化的路徑還是不錯的。
問:對於醫療產業來說,引入大模型的成本有多高?
劉軍偉:對我們來講,做這樣的靈醫大模型,客觀的來講成本可控。剛才我們說了有已有的這些能力,甚至在文心大模型預訓練的過程中,用一些閒置的資源就可以把靈醫大模型跑出來,這就是其他公司相對來說要從0-1去做,或者之前沒有大模型的積累甚至行業知識的話,相對有一定的門檻。
問:目前醫療機構對於大模型的付費意願如何?此前AI影像輔助診斷技術也是因為成本較高比較難商業化落地。
劉軍偉:這裡面醫療機構看分幾部分,第一就是大家理解傳統的公立醫院,現在也在探索,不管是剛才說的北大口腔,通過聯合課題的方式,我們現在跟復旦中山也在合作,通過部署我們的Lite輕量版本做一些合作。
其次關於醫療大模型的需求,首先我們在科研的場景看到大量的需求,另一方面我們也發現大模型在信息化方面,比如在病歷生成等方面有提升。
另一方面,我們也看到連鎖集團、藥店等ToB的場景的應用空間更大一些。公立醫院更代表嚴肅醫療,而ToB的場景裡面有更大的想像空間,比如網際網路醫院也有分導診、預問診。大家也反覆強調,**公立醫院積攢的產品的大模型能力,可以快速複製到ToB醫院的場景裡面去,增加我們商業化空間**。
問:劉總也提到很多公司他們是在蹭熱點,所以請教一個問題,怎麼判斷醫療AI大模型是不是靠譜,我們可以從哪些方面進行判斷?
劉軍偉:我認為從三個維度看一家公司在大模型方面是不是靠譜。
第一是不是有數據集的子評測,有沒有經過三甲醫生或者權威機構的認證。
第二有沒有開放產品讓大家體驗。很多公司其實沒有看到過產品,停留在研發階段。今天我們推出的靈醫BOT這樣的產品,大家可以真的去體驗測試。
第三個最重要的就是有真實的客戶案例,尤其是有商業化的合作,能夠說明行業的認可度。
(36氪作者海若鏡對本文亦有貢獻。)
長按添加「智涌」小助手入群
👇🏻 添加請備註:公司+職務 👇🏻
歡迎入群交流

歡迎交流!
歡迎交流!

























